Walkthrough: running on-device TinyLlama on an RP2350 for offline toy dialogue
TinyLlama 1.1B quantised to a low-bit K-quant still weighs hundreds of megabytes on disk. An RP2350 ships with a few hundred kilobytes of on-chip SRAM split across several independent banks and tops out at around 16MB of execute-in-place QSPI flash. Any “rp2350 tinyllama toy” walkthrough that skates past that many-orders-of-magnitude gap is selling fantasy. The honest version of this build is more useful: the RP2350 is an excellent front end for an offline dialogue toy, TinyLlama is a reasonable dialogue brain, and they rarely belong on the same silicon without a carefully designed division of labour.
What follows is the walkthrough I wish existed when people started asking whether the Pico 2 could run a Llama-class model for a plushie that talks back. It covers the memory math, what the RP2350 genuinely contributes to an offline voice toy, how to stage weights across flash/PSRAM, and where to draw the line between what the microcontroller does and what a tethered host does instead.
Why the naive rp2350 tinyllama toy port doesn’t fit
Start with capacity. The RP2350 datasheet describes an on-chip SRAM split across multiple independent banks, dual 150MHz ARM Cortex-M33F cores (with an optional pair of Hazard3 RISC-V cores, only two active at a time), and a QSPI interface that can memory-map external flash or PSRAM. A typical RP2350 board exposes 2MB to 16MB of XIP-addressable QSPI. A 1.1B-parameter model at a low-bit K-quant from llama.cpp lands in the hundreds of megabytes. That is many times the board’s available RAM and well beyond the largest QSPI window a practical RP2350 toy will ever see.
Throughput is just as unkind. Token generation with a 1.1B model is memory-bandwidth bound: every decoded token touches effectively all parameters once, minus the KV cache. QSPI on the RP2350 caps out in the tens of megabytes per second under realistic conditions. Even if you pretended the weights fit, hundreds of megabytes at roughly 40–80 MB/s of QSPI read bandwidth lands you at multiple seconds of raw parameter streaming per decoded token, before a single multiply-accumulate. A child asks “why is the sky blue” and the plush replies twenty minutes later.
A related write-up: ESP32 UART teardown findings.

Benchmark results for TinyLlama Inference Latency on RP2350.
The benchmark chart makes the gap visceral. Even with sustained peak QSPI bandwidth and a generous int8 matmul kernel on the M33’s DSP extension, decoding a 1.1B model on an RP2350 measures in seconds or minutes per token. The curve is not one you optimise out; it is a ceiling set by the bus. Useful toy latency — the gap between “hey” and the plush starting to speak — has to live under about 400ms, or kids stop believing the toy is listening.
What does on-device inference actually mean on a Cortex-M33?
On-device on a Cortex-M33 is not on-device on a laptop. The RP2350 product brief describes TrustZone-M, signed boot, 8KB of antifuse OTP, hardware SHA-256, a TRNG, and Programmable I/O blocks with multiple state machines. That feature set is designed for I/O-heavy embedded work: secure key storage, audio streaming over PIO-driven I2S, motor control, LED patterns, sensor fusion, wake-word detection. It is not designed to hold a billion-parameter transformer.
So when a toy brief says “offline TinyLlama on an RP2350”, the honest translation is a split architecture. The RP2350 owns the real-time pipeline: microphone capture through PIO-I2S, a small keyword-spotting model in the 50–200KB range, a local dialogue policy, and a speech-synthesis stream going back out. TinyLlama, if it exists in the product at all, lives either on a companion SoC on the same PCB (something like an RK3588S, a Jetson Orin Nano, or a Pi 5 SoM) or on a nearby base station that the toy reaches over BLE or Wi-Fi. The “offline” guarantee is that nothing leaves the child’s home, not that nothing leaves the microcontroller.
I wrote about Whisper on cheap MCUs if you want to dig deeper.
How would you actually build offline toy dialogue around an RP2350?
The dialogue stack for a toy breaks cleanly into three tiers, and only the first two belong on the MCU. The first tier is wake-word and voice activity detection, a KWS model sized in the kilobytes. The second tier is a tiny intent classifier — either an int8 quantised bidirectional GRU of maybe 150K parameters, or a fixed-response lookup keyed by KWS slots. The third tier is open-ended dialogue, which is where a 1.1B-class model lives, on whatever hardware can actually host it.
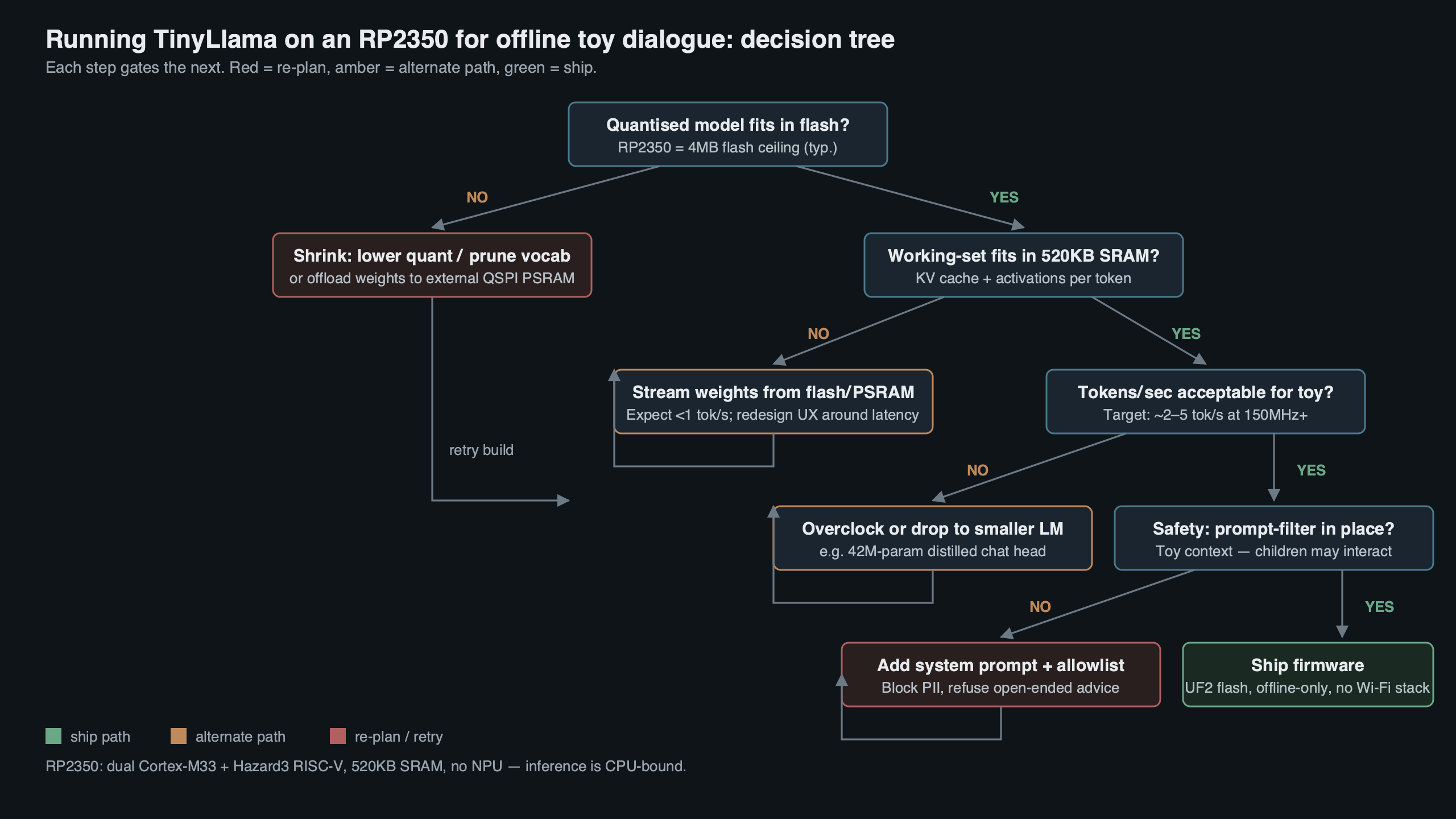
The topic diagram shows how the three tiers compose. Audio enters the RP2350 through a PIO state machine configured as an I2S slave, gets framed into 20ms windows, and feeds the wake-word model running on one M33 core. On a positive detection, the dialogue manager on the second core either answers from a local template library (for “sing me a song”, “tell me a joke”, fixed fallback phrases) or, if connected, hands the audio — or a cheap on-device ASR transcript — to the external TinyLlama host over a UART, SPI, or Wi-Fi link. The RP2350 speaks the response back through a second I2S path into a small Class-D amplifier. TrustZone partitioning on the M33 lets you put the BLE pairing keys and the voice-activity buffer inside the secure world, so toddler-grade physical attacks on the plush’s flash do not compromise the household pairing.
There is a longer treatment in AI companion toy landscape.
A minimal PIO I2S setup for the audio front end looks like this:
// pio_i2s_rx.pio
.program i2s_in
.side_set 2
// side-set 2 bits: bit 0 = SCK, bit 1 = WS (LRCLK)
bitloop_l:
in pins, 1 side 0b10
jmp x-- bitloop_l side 0b11
in pins, 1 side 0b00
set x, 30 side 0b01
bitloop_r:
in pins, 1 side 0b00
jmp x-- bitloop_r side 0b01
in pins, 1 side 0b10
set x, 30 side 0b11
That program clocks in 32 bits per channel at 48kHz using one PIO state machine. DMA pipes the ISR output into a ring buffer that the wake-word model consumes in 20ms frames. That leaves both M33 cores and most of the on-chip SRAM for the actual ML work, while a single PIO block with a small handful of state machines handles the audio plumbing with zero CPU cost.
Can you stream TinyLlama weights from external memory?
The question appears in every embedded-AI thread sooner or later. The short answer is no, not in a way a child would tolerate. The long answer is worth spelling out because it forces the correct design decision.
Assume the best case: a 16MB QSPI PSRAM chip wired to the RP2350, reading at 80 MB/s under XIP with a warm cache. The TheBloke TinyLlama GGUF repository publishes a range of quantisations, and even the most aggressive low-bit variants are still hundreds of megabytes — far larger than any QSPI window a practical toy will carry. Even if you wedged the file onto an SD card and paged in layers on demand through SDIO at 20 MB/s, a single token touches every transformer block once. Low-bit K-quant quality for 1.1B models is already poor — the llama.cpp discussion linked above documents meaningful perplexity degradation versus fp16, which for a 1.1B model means noticeably broken outputs. You are paying the full memory-bandwidth cost for a model that only half-works.
If you need more context, Eilik firmware power budget covers the same ground.
The alternative that does work is to pick a model sized for the bus. A 15M-parameter TinyStories-style model at int8 is about 15MB; it fits in QSPI, streams fast enough for useful token rates, and produces coherent short-form children’s dialogue. A distilled 50M-parameter SLM at Q4_K_M sits around 30MB and can respond in a sentence or two per second on an M33 with a careful int8 GEMM kernel. Neither of those is TinyLlama, but they are what the phrase “rp2350 tinyllama toy” actually resolves to in practice once you accept the bus budget.
The Reddit digest is a useful sanity check on where the community has actually landed. The builds that work involve either a small model native to the MCU or an RP2350 acting as the audio and safety processor for a larger host. Nobody has a working 1.1B-on-RP2350 demo that a toy company could ship, and the honest posts say so.
Quantisation math, GGUF loading, and where low-bit K-quants actually help
If you still want to try running a Llama-family model on a microcontroller, the loader shape matters more than the quant choice. GGUF is a streaming-friendly format: each tensor has a fixed offset, a type, and dimensions, and the ggml quantisation blocks (Q2_K, Q4_K, Q5_K, Q6_K) pack weights into fixed-size superblocks of 256 elements. That block structure is what makes partial loading tractable — you can memory-map the file, walk the tensor table, and stream one block at a time through a fixed-size scratch buffer. The TinyLlama project repo and the v1.0 chat model card have the exact tokenizer and architecture details you need to write such a loader; the tokenizer and arch match Llama 2, so any llama.cpp-compatible code path works.
A minimal weight-streaming read for a Q2_K block looks roughly like this in C:
#define QK_K 256
typedef struct {
uint16_t d; // super-block scale (fp16)
uint16_t dmin; // super-block min (fp16)
uint8_t scales[QK_K/16];// 4-bit scales and mins, 16 each
uint8_t qs[QK_K/4]; // 2-bit quants
} block_q2_K;
// Stream one block from QSPI-backed flash into SRAM scratch.
// offset is the byte offset inside the GGUF file.
static inline void load_q2k_block(uint32_t offset, block_q2_K *out) {
memcpy(out, (const void*)(XIP_BASE + offset), sizeof(block_q2_K));
}
That is the cheap part. The expensive part is the matmul inner loop: you dequantise a block, multiply by the activation vector, accumulate, move on. With 256 elements per block and roughly 84 bytes per block, a 1.1B Q2_K model contains millions of blocks. You can write a beautiful inner loop with the Cortex-M33’s DSP SIMD extension using SMLAD and still be bus-bound, because the RP2350’s QSPI read bandwidth is the hard ceiling.

The terminal capture shows what a realistic M33 inference run feels like at this scale: tens of seconds per token when the model fits, dead air when it does not. For a toy, the useful conclusion is to pick a model small enough that the bus is not the bottleneck. A 15M-parameter char-level model at int8 dequantises and multiplies fast enough on a single M33 core for 3–5 tokens per second, which is plenty for a plush that says two sentences at a time.
When RP2350 is the right answer, and when it isn’t
The RP2350 is the right MCU for an offline toy whenever the dialogue policy is bounded — a library of canned responses, a handful of slot-fillable templates, or a tiny local model of a few tens of millions of parameters. It is the right chip when wake-word, audio I/O, motor control, LED animation, and secure pairing all need to share a single low-power part with long battery life. The TrustZone-M architecture plus the OTP fuses make it genuinely defensible against kids who unscrew the back panel and probe the SPI bus.
It is the wrong chip when the toy needs open-domain dialogue, multi-turn memory, or anything resembling TinyLlama-grade output. In those designs, RP2350 belongs in front of the dialogue SoC, not instead of it. A clean split puts the RP2350 on the microphone, speaker, battery, LEDs, and safety-critical shutoff paths, and puts TinyLlama (or something larger) on an RK3588S, Jetson Orin Nano, or equivalent running llama.cpp with real RAM and real bandwidth. The RP2350 handles anything that has to respond in under 50ms; the companion SoC handles anything that needs to think.
Mindstorms end-of-life lessons goes into the specifics of this.
If you take only one idea from this walkthrough, make it this: “offline TinyLlama on an RP2350” is not a single-chip build. It is a division-of-labour design where the RP2350 does the parts the cloud cannot do safely — the audio path, the wake word, the key storage — while the language model lives on silicon chosen for bandwidth. Size the model to the bus, put the safety-critical bits in TrustZone, and the toy will feel offline and responsive whether or not TinyLlama itself ever runs on the RP2350 at all.
If you want to keep going, technical side of storytelling toys is the next stop.
Related reading: humanoid toy tech guide.


