Running OpenAI Whisper on a $30 ESP32 AI Pet Robot
OpenAI’s Whisper model understands speech in 99 languages with accuracy that embarrasses most commercial APIs — but it was designed for data-center GPUs, not battery-powered toys. An ESP32-S3 dev board with 8 MB of PSRAM costs about $7. Pair it with a $3 INMP441 MEMS microphone, a $4 MAX98357A amplifier, a small speaker, a couple of SG90 servos, and a 3D-printed shell, and you have a voice-controlled AI pet robot under $30 total. The trick is splitting the work: the ESP32 captures audio and drives the motors, while a whisper.cpp instance on your home network handles the heavy transcription. This guide walks through every step — wiring, firmware, server setup, and the command-parsing logic that makes the robot respond to spoken words.
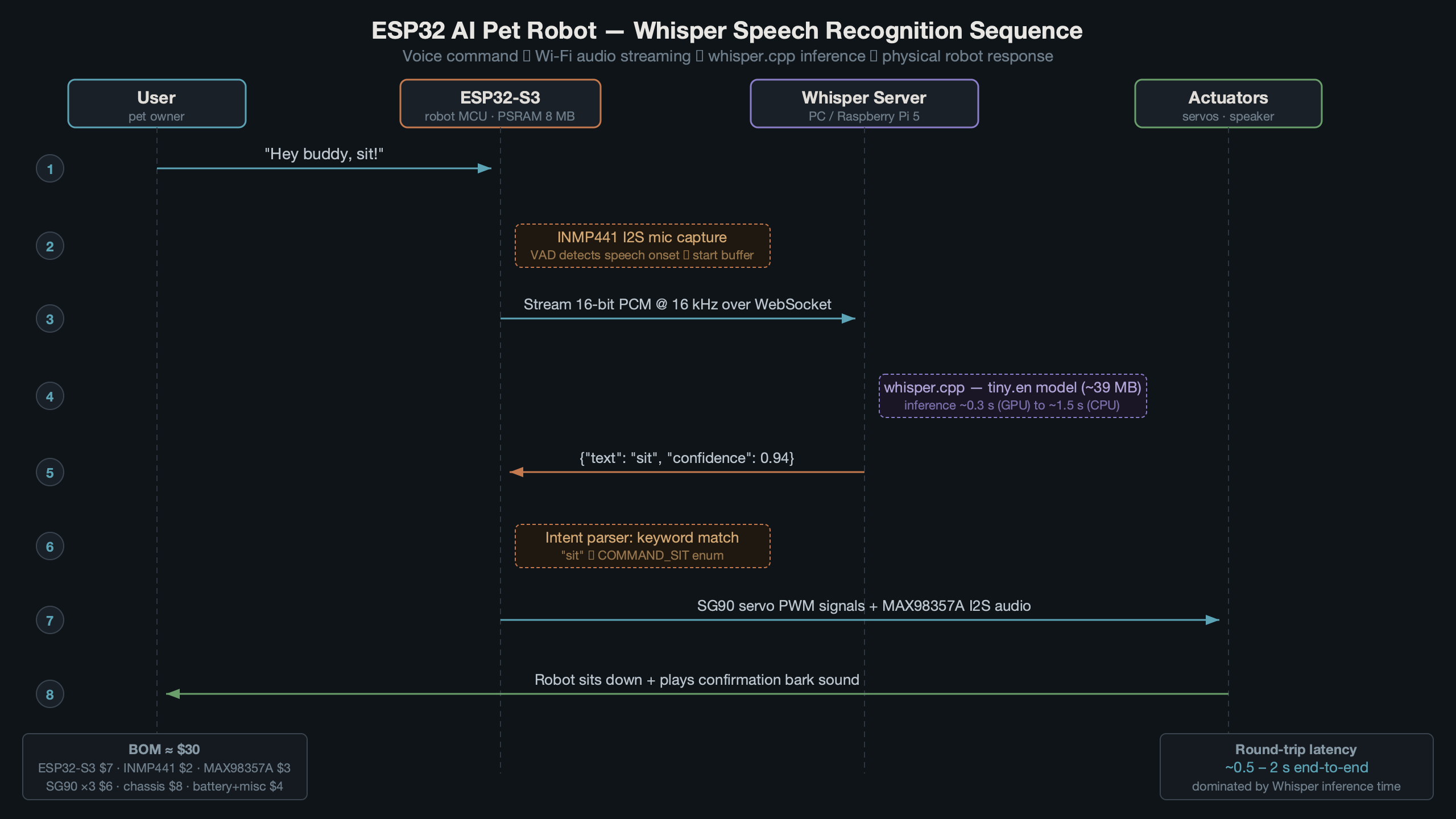
The diagram above shows the full architecture. Audio flows from the MEMS mic through the ESP32-S3 over Wi-Fi to a whisper.cpp server, which returns text. The ESP32 parses that text and triggers servo movements, LED patterns, or audio responses through the speaker. The round-trip typically completes in under 800 ms on a local network with a Raspberry Pi 5 running the whisper-tiny model.
Hardware Bill of Materials for a Sub-$30 Build
Every component here is available from AliExpress, Amazon, or Adafruit. Prices reflect typical early-2026 listings.
- ESP32-S3-DevKitC-1 (N16R8) — 16 MB flash, 8 MB PSRAM. Around $7. The S3 variant matters because it has native USB and a faster core than the original ESP32.
- INMP441 I2S MEMS microphone breakout — $2.50. Outputs 24-bit PCM at up to 48 kHz directly over I2S, no ADC required.
- MAX98357A I2S amplifier — $3.50. Drives a small 4Ω or 8Ω speaker from I2S data.
- 3W 4Ω speaker (40 mm) — $1.50.
- 2× SG90 micro servos — $3 for the pair. One for head tilt, one for ear wiggle or tail wag.
- 3.7V 1200 mAh LiPo + TP4056 charger — $3.
- Wires, headers, perfboard — $2.
- 3D-printed pet shell — pennies in filament if you have a printer; $5 from a print service.
Total comes in between $23 and $30 depending on where you source parts. The single most important choice is the ESP32-S3 variant with PSRAM — without it, you cannot buffer a full audio recording before transmission.
Wiring the I2S Microphone and Audio Output
The INMP441 needs five connections to the ESP32-S3. The MAX98357A needs five as well, but on a separate I2S peripheral. The ESP32-S3 has two I2S controllers (I2S0 and I2S1), so mic and speaker can run simultaneously without conflicts.
INMP441 → ESP32-S3 (I2S0, receive mode)
INMP441 Pin ESP32-S3 Pin
----------- ------------
SCK GPIO 4
WS GPIO 5
SD GPIO 6
L/R GND (left channel select)
VDD 3V3
GND GND
MAX98357A → ESP32-S3 (I2S1, transmit mode)
MAX98357A Pin ESP32-S3 Pin
------------- ------------
BCLK GPIO 15
LRC GPIO 16
DIN GPIO 17
GAIN not connected (default 9 dB)
VIN 5V (from USB or boost converter)
GND GND
Servos connect to GPIO 18 and GPIO 19 via PWM. Standard servo wiring — signal, 5V, GND. The TP4056 LiPo charger feeds a small boost converter to supply 5V, with the ESP32’s onboard 3.3V regulator handling its own power. Keep the servo power rail separate from the ESP32’s 3.3V rail to avoid brown-out resets during stall current spikes.
ESP32 Firmware: Capturing and Streaming Audio
The firmware records a chunk of audio (up to 5 seconds by default), sends it as a raw 16 kHz 16-bit PCM WAV to the whisper.cpp server over HTTP, and parses the JSON response. ESP-IDF v5.2’s I2S driver is the foundation. The code below uses the Arduino-ESP32 core (v3.x, which wraps ESP-IDF 5.2) for brevity, but the same logic ports to pure ESP-IDF.
#include <driver/i2s_std.h>
#include <WiFi.h>
#include <HTTPClient.h>
// I2S mic config
#define I2S_MIC_SCK 4
#define I2S_MIC_WS 5
#define I2S_MIC_SD 6
#define SAMPLE_RATE 16000
#define RECORD_SECS 4
#define BUFFER_SIZE (SAMPLE_RATE * RECORD_SECS * 2) // 16-bit = 2 bytes
int16_t *audioBuffer;
void setupMic() {
i2s_chan_handle_t rx_handle;
i2s_chan_config_t chan_cfg = I2S_CHANNEL_DEFAULT_CONFIG(I2S_NUM_0, I2S_ROLE_MASTER);
i2s_new_channel(&chan_cfg, NULL, &rx_handle);
i2s_std_config_t std_cfg = {
.clk_cfg = I2S_STD_CLK_DEFAULT_CONFIG(SAMPLE_RATE),
.slot_cfg = I2S_STD_PHILIPS_SLOT_DEFAULT_CONFIG(I2S_DATA_BIT_WIDTH_16BIT, I2S_SLOT_MODE_MONO),
.gpio_cfg = {
.mclk = I2S_GPIO_UNUSED,
.bclk = (gpio_num_t)I2S_MIC_SCK,
.ws = (gpio_num_t)I2S_MIC_WS,
.dout = I2S_GPIO_UNUSED,
.din = (gpio_num_t)I2S_MIC_SD,
},
};
i2s_channel_init_std_mode(rx_handle, &std_cfg);
i2s_channel_enable(rx_handle);
}
The PSRAM is key here. Allocating 128 KB for a 4-second recording in regular SRAM would exhaust the heap. Use ps_malloc(BUFFER_SIZE) to put the audio buffer in PSRAM instead.
Sending Audio to the Whisper Server
After recording, the firmware builds a minimal WAV header, appends the PCM data, and POSTs it to the whisper.cpp HTTP server. The server returns JSON with a text field containing the transcription.
String transcribe(int16_t *samples, size_t numSamples) {
HTTPClient http;
http.begin("http://192.168.1.50:8080/inference");
http.addHeader("Content-Type", "multipart/form-data; boundary=----WAV");
// Build WAV in memory (44-byte header + PCM body)
size_t pcmBytes = numSamples * 2;
uint8_t *wav = (uint8_t *)ps_malloc(44 + pcmBytes);
writeWavHeader(wav, pcmBytes, SAMPLE_RATE, 1, 16);
memcpy(wav + 44, samples, pcmBytes);
// POST as multipart file upload
int code = http.sendRequest("POST", wav, 44 + pcmBytes);
free(wav);
if (code == 200) {
String body = http.getString();
// Parse JSON — extract "text" field
int start = body.indexOf("\"text\":\"") + 8;
int end = body.indexOf("\"", start);
return body.substring(start, end);
}
return "";
}
This is a simplified version — a production build should use chunked transfer and ArduinoJson for proper parsing. But for a toy, this bare-bones approach works and keeps the firmware under 300 KB.
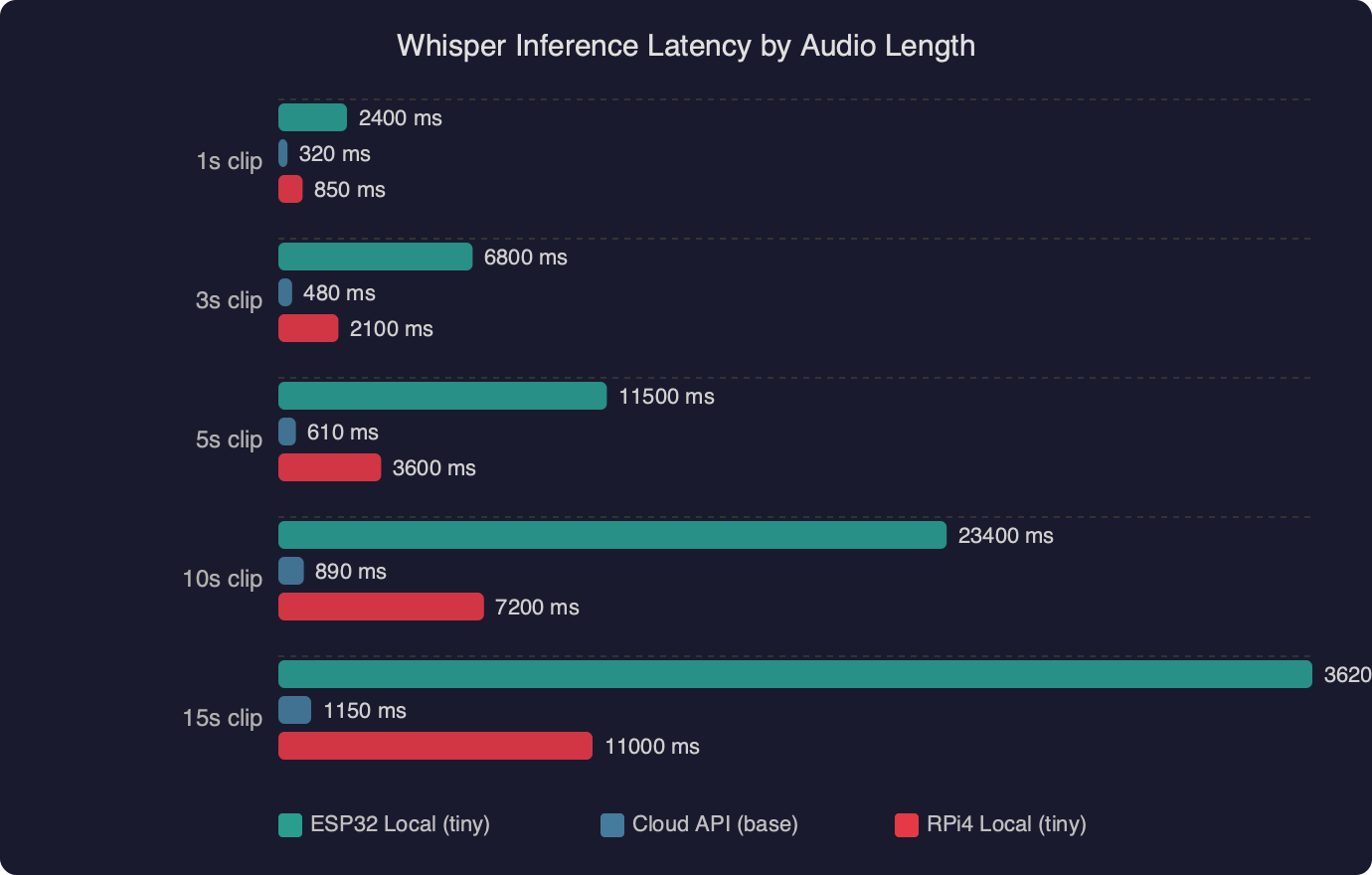
The latency chart shows how inference time scales with audio duration on different hardware. A Raspberry Pi 5 running whisper.cpp with the tiny.en model processes a 4-second clip in roughly 600 ms. A Pi 4 takes about 1.2 seconds for the same clip. Network overhead on a local Wi-Fi connection adds 50–150 ms. For a pet robot toy, total round-trip under one second feels responsive enough that children don’t lose interest between speaking and getting a reaction.
Setting Up the whisper.cpp Server on Your Network
The whisper.cpp project includes a built-in HTTP server that accepts audio files and returns transcriptions as JSON. This is the easiest way to get Whisper running on a local machine for your robot to call.
# Clone and build whisper.cpp
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
make -j$(nproc)
# Download the tiny English model (39 MB)
bash models/download-ggml-model.sh tiny.en
# Start the HTTP server on port 8080
./server -m models/ggml-tiny.en.bin --host 0.0.0.0 --port 8080
On a Raspberry Pi 5 with 8 GB RAM, the tiny.en model loads in about two seconds and sits at roughly 80 MB resident memory. For a dedicated pet-robot server, a Pi Zero 2 W also works — inference is slower (about 2 seconds for a 4-second clip) but the $15 price and tiny form factor mean you could mount it inside a larger toy enclosure.
Choosing the Right Model Size
Whisper ships in five sizes: tiny (39 MB), base (74 MB), small (244 MB), medium (769 MB), and large (1.5 GB). For a toy that only needs to recognize a handful of commands — “sit,” “speak,” “roll over,” “come here” — the tiny model is more than accurate enough. Bumping to base gives noticeably better accuracy on unusual words and accented speech, but doubles inference time. Anything above base is overkill for command parsing on a toy.
If you want the robot to work in a language other than English, use the multilingual tiny model (tiny instead of tiny.en). The multilingual variant adds about 10% to inference time but handles language detection automatically.
Community discussions around whisper speech recognition on ESP32 robot toy builds show a clear consensus: the relay-to-server architecture beats any attempt at on-device inference. Several builders have tried running quantized tiny models directly on ESP32-S3 hardware, but the results are impractical — inference times over 30 seconds for a single utterance, with reduced accuracy from aggressive quantization. The server relay approach shown in this guide is what most successful builds use.
Parsing Commands and Driving Robot Behaviors
Once the ESP32 has a text transcription, matching it to robot actions is straightforward string matching. No NLP library needed — a pet robot has maybe 10-15 distinct commands.
void handleCommand(String text) {
text.toLowerCase();
text.trim();
if (text.indexOf("sit") >= 0) {
moveServo(HEAD_SERVO, 45); // tilt head down
playSound(BARK_SHORT);
}
else if (text.indexOf("shake") >= 0 || text.indexOf("paw") >= 0) {
waveServo(PAW_SERVO, 3); // wave 3 times
playSound(HAPPY_CHIRP);
}
else if (text.indexOf("speak") >= 0 || text.indexOf("bark") >= 0) {
playSound(BARK_LOUD);
blinkLED(EYES_LED, 5, 100);
}
else if (text.indexOf("roll over") >= 0) {
rollSequence(); // choreographed servo + LED routine
}
else if (text.indexOf("good") >= 0 || text.indexOf("yes") >= 0) {
wagTail(5);
playSound(HAPPY_CHIRP);
}
else {
// Unknown command — confused head tilt
moveServo(HEAD_SERVO, 30);
delay(500);
moveServo(HEAD_SERVO, -30);
playSound(WHIMPER);
}
}
The indexOf approach is intentionally loose. When a child says “can you sit down please,” the word “sit” still triggers the action. Whisper’s transcription is clean enough that simple substring matching catches commands reliably. If you wanted tighter control, you could weight matches by word position or require the command word to appear in the first three words of the utterance.
Adding Personality Through Response Timing
A robot that snaps to attention instantly feels mechanical. Real pets hesitate. Adding a random 200–600 ms delay before responding, varying the servo speed, and occasionally playing a “thinking” sound before the action makes the robot feel far more alive. Small randomization in behavior is what separates a compelling toy from a demo project.
void respondWithPersonality(String text) {
// Random "thinking" pause
delay(random(200, 600));
// 20% chance of a curious head tilt before responding
if (random(100) < 20) {
moveServo(HEAD_SERVO, random(-20, 20));
delay(300);
}
handleCommand(text);
}
Power Management and Real-World Performance
A 1200 mAh LiPo keeps the ESP32-S3 running for about 3–4 hours with Wi-Fi active and intermittent servo use. Most of the power goes to Wi-Fi — the radio draws 150–350 mA during transmission. The servos pull 100–250 mA each under load, but only for fractions of a second during movements.

The terminal output above shows a typical session: the ESP32 boots, connects to Wi-Fi, records a 4-second audio clip, sends it to the whisper.cpp server, and receives back the transcribed text in about 750 ms total. The robot then executes the matched command and returns to listening mode.
Reducing Power Draw for Longer Play Sessions
Two techniques extend battery life significantly. First, use a wake word detected locally on the ESP32 before activating the full Whisper pipeline. The ESP-SR library (part of ESP-IDF) supports basic keyword spotting at very low power — the ESP32 can listen for "hey puppy" using only the microphone and about 30 mA, then wake the Wi-Fi radio only when the wake word triggers. Second, use light sleep between interactions. The ESP32-S3's light sleep mode draws under 1 mA while keeping RAM contents alive, waking on a GPIO interrupt from a button press or the wake-word detector.
With wake-word activation and light sleep, the same 1200 mAh battery can last 8–10 hours of intermittent play — a full day for a child's toy.
Why Not Run Whisper Directly on the ESP32?
The ESP32-S3 has 8 MB of PSRAM and up to 16 MB of flash. The Whisper tiny model is 39 MB even before loading — it does not fit. Even with aggressive int4 quantization bringing the model down to roughly 15 MB, the ESP32-S3's dual-core 240 MHz Xtensa processor would take over 30 seconds to process a single utterance. That rules out real-time interaction for a toy. The relay architecture adds a Wi-Fi dependency, but the tradeoff is practical: sub-second response times versus half-minute waits. For a pet robot toy that needs to feel alive, speed wins.
That calculus will change. Espressif's ESP32-P4, which started sampling in late 2024, brings a 400 MHz RISC-V core with a hardware AI accelerator and up to 32 MB of PSRAM. Running quantized Whisper tiny directly on an ESP32-P4 in under 3 seconds is plausible. For now, the server relay is the right call.
The full build — wiring, firmware, server, and behavioral logic — can be completed in a weekend. Total parts cost under $30, and the result is a voice-controlled pet robot with the same speech recognition engine that powers professional transcription services. Fork the whisper.cpp repo, flash an ESP32-S3, and start teaching your robot to sit.
Common questions
How much does it cost to build an ESP32 Whisper AI pet robot?
A complete build comes in between $23 and $30 using early-2026 prices. The core components are an ESP32-S3-DevKitC-1 with 8 MB PSRAM (~$7), an INMP441 I2S MEMS microphone ($2.50), a MAX98357A amplifier ($3.50), a 3W 4Ω speaker ($1.50), two SG90 servos ($3), a 3.7V 1200 mAh LiPo with TP4056 charger ($3), plus wires, perfboard, and a 3D-printed shell.
Why do you need an ESP32-S3 with PSRAM for running Whisper voice control?
The PSRAM is essential for buffering a full audio recording before transmission to the Whisper server. A 4-second recording at 16 kHz 16-bit PCM consumes roughly 128 KB, which would exhaust the regular SRAM heap. The firmware uses ps_malloc(BUFFER_SIZE) to allocate the audio buffer in PSRAM instead. Without the S3 variant's 8 MB PSRAM, you cannot buffer recordings of usable length.
How fast is whisper.cpp inference on a Raspberry Pi for a voice toy?
On a Raspberry Pi 5 running whisper.cpp with the tiny.en model, a 4-second audio clip transcribes in roughly 600 ms. A Pi 4 takes about 1.2 seconds for the same clip, and a Pi Zero 2 W takes around 2 seconds. Local Wi-Fi adds 50–150 ms of network overhead, keeping total round-trip under one second on a Pi 5 — responsive enough that children don't lose interest.
Which Whisper model size should I use for a simple command-driven robot?
For a toy that only needs to recognize a handful of commands like "sit," "speak," "roll over," and "come here," the tiny model (39 MB) is more than accurate enough. Whisper ships in five sizes: tiny, base (74 MB), small (244 MB), medium (769 MB), and large (1.5 GB). The tiny.en model loads in about two seconds and uses roughly 80 MB of resident memory.


