
Inside Wake Words and VAD for Offline AI Plush Assistants
Last updated: May 10, 2026
An offline plush wake word is a local keyword detector that lets a smart stuffed toy stay mostly asleep until it hears a specific phrase. VAD detects speech-like sound; it does not prove the child meant to talk to the toy. The practical test is where each gate decides: local VAD, local wake word, local command handling, or a cloud handoff that may send audio parents thought stayed offline.
- VAD is the speech gate; wake-word detection is the intent gate; cloud revalidation is the privacy-risk gate.
- Espressif’s WakeNet documentation describes 16 kHz mono PCM, 16-bit audio, and 30 ms frames for embedded wake-word processing.
- Picovoice reports a standard Porcupine wake-word model around 1 MB and under 4% of one Raspberry Pi 3 core.
- An offline plush wake word claim should say whether any pre-wake ring buffer ever leaves the toy.
- The FTC’s 2017 COPPA voice-recording guidance treats audio containing a child’s voice as personal information, with narrow limits for brief command use.
What An Offline Plush Wake Word Actually Does
An offline plush wake word is a small, local audio classifier. It listens for a fixed phrase such as “Hey Bear,” “Okay Milo,” or “Lumi, wake up,” then opens a response path. That response path might be a fully local story mode, a local command menu, or a cloud conversation. The wake word being offline does not mean the whole AI plush assistant is offline.
This distinction matters because parents, toy designers, and reviewers often collapse several different claims into one label. “Listens locally” may only mean the first trigger phrase is processed on the toy. It may not mean the toy’s speech recognition, safety filtering, memory, chatbot response, or analytics are local. A toy can have an offline plush wake word and still upload the child’s next sentence after the trigger phrase.
Official wake-word documentation shows how compact the wake layer can be. Picovoice says its Porcupine engine is meant for always-listening applications, supports devices from Arm Cortex-M boards to Raspberry Pi and mobile platforms, and can test a custom wake phrase in a browser even with Wi-Fi turned off because voice processing runs in the browser itself. Its FAQ reports a standard model size around 1 MB and less than 4% of a Raspberry Pi 3 core for one trim. Google’s TensorFlow Lite Micro micro_speech example shows another end of the scale: a tiny “yes/no” recognizer with a model under 20 KB, and example source has used a 10 KB tensor arena for input, output, and intermediate arrays.
For buyers and reviewers, the simple question is what happens after the phrase is detected. A bedtime bear that says “story time” from local storage is a different product from an AI companion plush that sends a child’s open-ended question to a remote model.
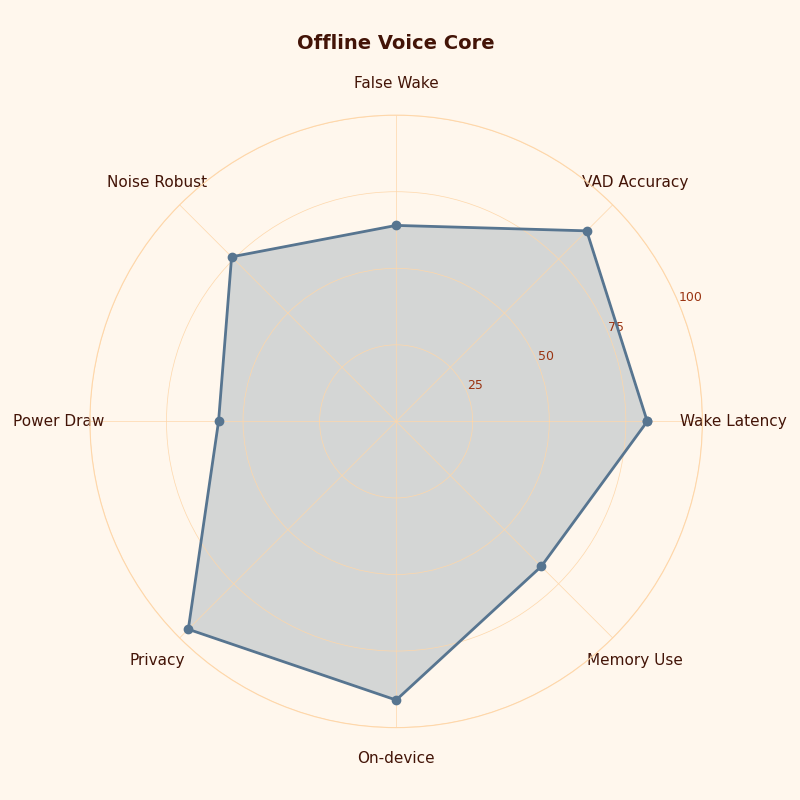
The radar chart should be read as an architecture pressure map. A plush voice core is not judged on one axis; privacy, latency, battery draw, child speech tolerance, and local command coverage pull against each other. A product that scores high on cloud conversation may still score poorly on buffer exposure if the wake gate is loose.
VAD Is The Speech Gate, Not The Intent Gate
Voice activity detection answers a narrow question: does this audio frame look like speech? Wake-word detection answers a different question: did someone say the activation phrase? Treating VAD as proof of intent is the design mistake behind chatty, battery-hungry, privacy-confusing AI toys.
In a plush assistant, VAD is usually there to save power and reduce junk audio. It can keep the main processor asleep while a low-power audio front end watches for speech-like sound. It can also stop a conversation turn when the child stops talking. Google’s WebRTC VAD interface, for example, exposes voice probabilities and RMS values for chunks of audio; those are speech-likelihood and level measurements, not phrase recognition.
Wake-word or keyword spotting is the next gate. The wake detector receives short windows of audio, extracts acoustic features, and produces a score for a target phrase. Espressif’s WakeNet documentation describes MFCC feature extraction from 16 kHz mono signed 16-bit input, 30 ms frame width and step size, and a smoothing method where a trigger is sent only after an averaged recognition result crosses a threshold. That threshold is the intent gate. It is still imperfect, but it is at least trained around a specific phrase.
The difference shows up fast in toys. A VAD can fire on TV dialogue, a sibling across the room, or the plush’s own speaker. A wake-word detector should reject most of that unless it resembles the trigger phrase. If a toy routes every VAD event to a cloud recognizer, it is not behaving like an offline wake-word plush; it is using local speech detection as a microphone upload gate.
I treat vendor claims as hypotheses until the gates are named. “On-device listening” is not enough. The useful specification says: VAD runs locally, wake-word scoring runs locally, speaker verification is either absent or local, fixed safety commands run locally, and cloud handoff only happens after a named activation rule.
The Three-Gate Audio Pipeline Inside A Plush Assistant
The clean way to inspect an offline plush wake word is to draw the audio path as gates. Each gate receives audio or scores, makes one decision, and sends the toy toward “stay asleep,” “local command mode,” or “cloud handoff.” If the gate map is missing, the privacy and battery claims are mostly marketing.
| Stage | Input | Decision | Normal output | Toy-specific risk |
|---|---|---|---|---|
| Microphone front end | Microphone PCM from a port, grille, or fabric-covered opening | Is the signal clean enough to score? | Filtered PCM into a short audio ring buffer | Stuffing, hugs, drops, and blocked mic holes reduce speech clarity before AI sees anything. |
| VAD gate | Audio frames plus energy and speech-likelihood features | Is there speech-like sound? | Stay asleep, or wake a higher-power wake-word path | TV speech and toy-speaker playback can keep the toy awake and drain batteries. |
| Wake-word gate | VAD-approved audio plus wake-word score | Did the child say the trigger phrase? | Stay asleep, local command mode, or request another check | Whispers, shouting, accents, and young voices can increase missed wakes. |
| Buffer and routing gate | Audio ring buffer, wake-word score, parent settings, network state | Does any buffered audio leave the toy? | Local command mode or cloud handoff | A false wake can expose speech if the buffer is uploaded for revalidation. |
The audio ring buffer is the part many product pages omit. A plush assistant usually keeps a rolling slice of recent audio so the recognizer can include the start of a phrase. That buffer can stay in RAM and be discarded, or it can be packaged with the post-wake sentence and sent out. The difference is the difference between an offline-first toy and a toy that only has a local front door.
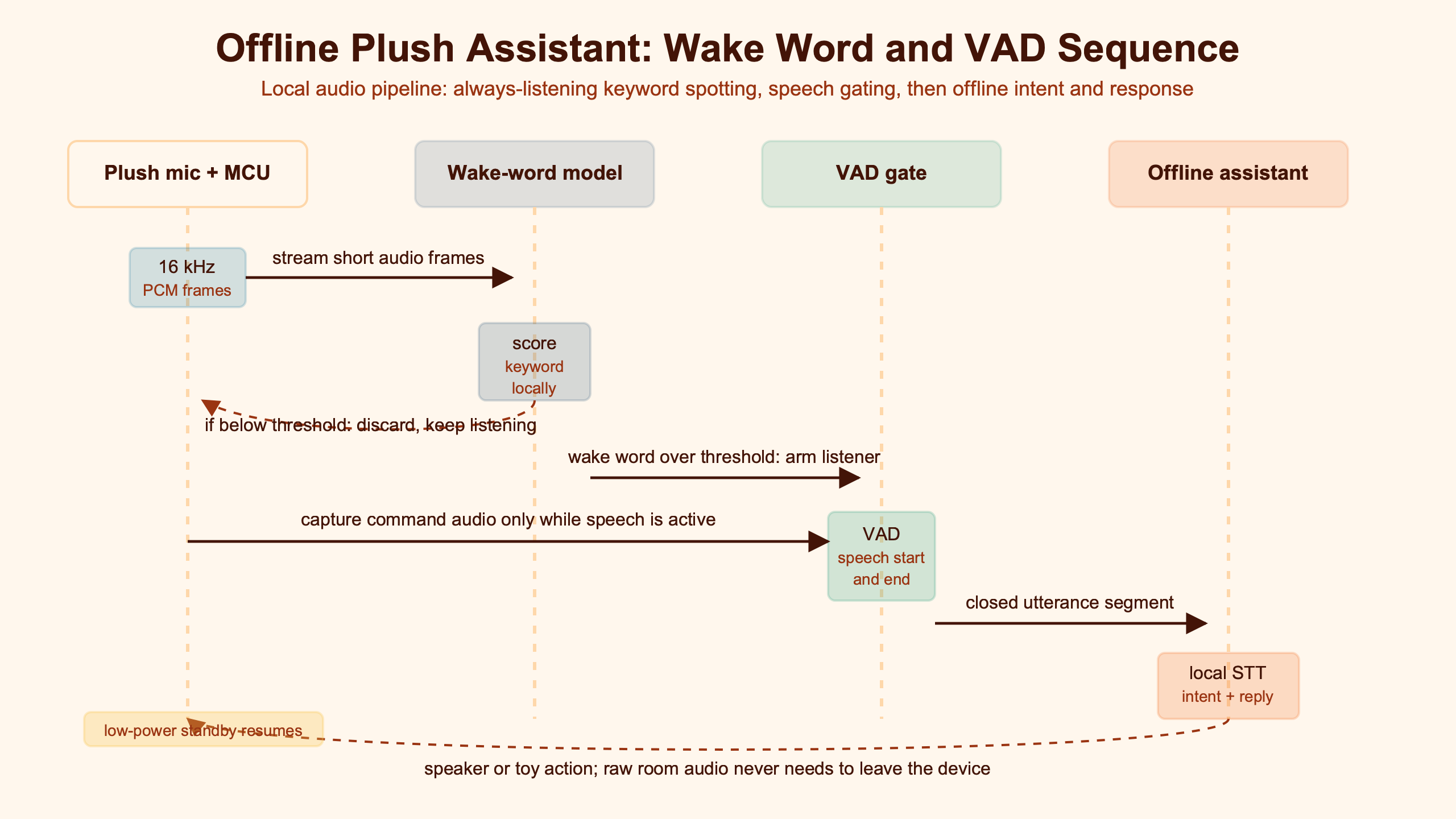
Purpose-built diagram for this article — Inside Wake Words and VAD for Offline AI Plush Assistants.
The diagram shows the point that matters: microphone PCM is not a privacy event by itself if it stays in volatile local memory and is discarded. Privacy exposure begins when the buffer crosses a boundary, usually at cloud handoff or cloud revalidation. A good review of an offline plush wake word should follow that arrow, not stop at the wake model badge.
Open-source wake-word projects make the gate split visible. openWakeWord describes an optional VAD threshold that only allows a positive wake prediction when the VAD score is also above a set value, reducing activations from non-speech noise. It also defines false rejects as missed intended activations and false accepts as unwanted activations, with example target levels below 5% false rejects and below 0.5 false accepts per hour for some included models after tuning. Those are not plush-specific guarantees, but they are the right metric names.
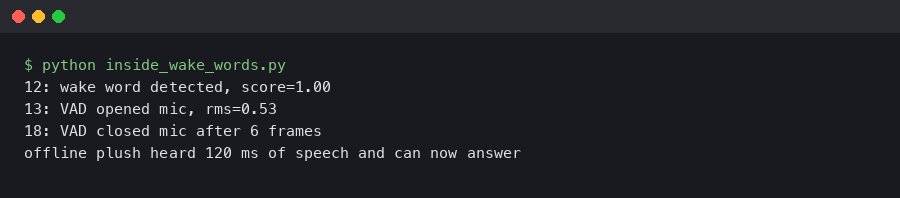
The terminal-style artifact is useful because it turns a fuzzy “it heard me” moment into observable gate events. A useful prototype log should show a VAD score, wake-word score, buffer decision, and response route. If the only visible event is “assistant started,” the team cannot tell whether a miss came from fabric damping, VAD thresholding, phrase scoring, or cloud routing.
Where Privacy Is Won Or Lost: The Audio Buffer Decision
Privacy is won or lost at the buffer-routing gate. Local wake-word scoring is helpful, but it is not the whole answer. The privacy-risk gate is the rule that decides whether pre-wake or post-wake audio leaves the plush after an uncertain trigger.
The FTC’s 2017 COPPA voice-recording guidance is the right baseline for child-directed connected toys in the United States. The agency said COPPA requires verifiable parental consent before collecting an audio recording from children under 13, while also describing a narrow enforcement policy for brief audio files used only as a substitute for written commands and then deleted. That policy has limits: it does not cover asking for personal information by voice, and operators still need clear notice and deletion disclosures.
For an AI plush assistant, that means the privacy spec should not say only “wake word runs locally.” It should answer these questions in plain product language: how long the ring buffer is, whether it includes audio before the trigger, whether false wakes are uploaded for server-side checking, whether the child’s command is stored, whether the toy keeps transcripts, and whether parent approval is required before open-ended chat.
Cloud revalidation is easy to bury in friendly wording. The local model may detect “Hey Bear,” then the server may re-check the audio before allowing the session. That can reduce false wakes, but it also sends the very audio segment parents may have assumed stayed inside the toy. The design is not automatically bad; it is simply not the same as a fully offline fixed-command plush.
A local reject layer changes the risk. If the toy hears TV speech, gets a weak wake-word score, and discards the ring buffer locally, the parent’s privacy exposure is low. If the toy uploads weak triggers for cloud revalidation, the exposure depends on buffer length, content, retention, and account controls. The wake word is only one part of the privacy story.
Why Plush Toys Break Smart-Speaker Assumptions
A smart speaker sits on a table with a known enclosure, fixed power, and often multiple microphones. A plush toy gets squeezed, covered by blankets, dropped on carpet, carried at lap height, and placed beside its own speaker. Those physical facts can matter as much as the wake model.
Fabric is an acoustic filter. Stuffing can shift around a microphone cavity. A stitched mouth or decorative nose can block a port after washing or rough play. A rigid smart speaker can separate microphones from drivers; a plush may put a tiny speaker, microphone, battery, and board in the same soft body. When the toy tells a story, its own voice can feed back into the microphone and produce VAD activity or wake-like syllables.
Children’s speech adds another layer. A 2022 systematic literature review in Applied Sciences reviewed 76 papers from 2009 to 2020 and describes children’s speech recognition as difficult because children differ from adults in articulatory, acoustic, physical, and linguistic characteristics. A separate Frontiers review from 2019 notes that school-age children often struggle to understand speech when competing sounds are present, especially speech. Those findings are about human and machine recognition in broader settings, but they map directly onto toy rooms full of siblings, TV sound, and bedtime whispers.
The result is a toy-specific failure pattern. A child may whisper the wake phrase at bedtime, shout it from across the room, say it with missing consonants, or speak while hugging the plush against a blanket. The model does not receive a clean phrase; it receives whatever the microphone port captures after fabric, body position, echo, and handling noise.
Toy safety also touches the voice stack. The CPSC’s toy safety FAQ says toys for children 12 and under require third-party testing and certification for applicable children’s product safety rules, and it identifies ASTM F963-23 as effective April 20, 2024. That is not a wake-word accuracy standard, but it reminds AI toy teams that microphones, speakers, batteries, stuffing, seams, and sound output live in a regulated child product, not a desktop prototype.
Choosing The Right Offline Architecture For A Toy
The right architecture depends on the promise the toy makes. A no-internet bedtime storytelling bear should not use the same audio route as an AI companion plush with optional cloud chat. The first needs predictable local commands. The second needs a clear handoff boundary and parent-controlled cloud use.
How I evaluated this
I checked primary and near-primary sources on May 10, 2026: wake-word vendor documentation, embedded speech documentation, open-source wake-word docs, child speech research, FTC voice-recording guidance, and CPSC toy safety guidance. I included sources that name a gate, metric, or regulatory duty. The comparison dimensions are privacy exposure, latency, battery risk, and child-speech risk. The limitation is that vendor figures are not plush lab tests; a soft toy enclosure can change the result.
| Architecture | Best fit | What decides locally | What may leave the plush | Main latency and battery risk | Child-speech risk |
|---|---|---|---|---|---|
| Fully offline fixed-command plush | Bedtime storytelling bear, calming toy, classroom prompt toy | VAD, wake word, command set, response selection | Nothing during normal use; diagnostics only if parent exports them | Battery risk comes from always-on listening and speaker playback, not network wait | High if the command set was tuned on adult voices only |
| Offline wake plus cloud conversation | AI companion plush with parent-enabled chat, language practice toy, AI learning toy | VAD, wake word, mute state, local stop command, basic safety commands | Post-wake child utterance after activation; pre-wake buffer only if disclosed and allowed | Network adds delay; battery cost rises during Wi-Fi and speaker turns | Medium to high because child speech affects both local wake and cloud ASR |
| Cloud-revalidated wake word | High-noise toy rooms where false wakes must be reduced and parents accept upload | Initial VAD and initial wake-word score | Buffered audio around uncertain wake events, depending on policy | Extra round trip before response; repeated false wakes can drain battery | Medium: server check may help, but weak child speech can still be rejected |
For a bedtime storytelling bear with no internet, I would choose a fully offline fixed-command design. The wake phrase should be long enough to avoid random matches but short enough for a sleepy child. The toy should accept local commands such as “story,” “again,” “softer,” and “stop,” with a physical mute switch. The ring buffer should stay in volatile memory and be discarded after each decision. This stops being the right choice when the product promise shifts to open-ended conversation or fresh factual answers.
For an AI companion plush with optional cloud chat, I would keep VAD, wake word, stop, mute, and parent-lock commands local. Cloud chat should begin only after a local wake and a visible or audible session cue. A parent setting should decide whether chat is available at all, and the toy should still respond locally to “stop” even if the network is down. This stops being the right choice for preschool toys where open-ended cloud conversation creates more risk than value.
The PyPI download-stat artifact is a caution, not a scorecard. Package popularity, install counts, or developer buzz do not prove a wake stack is safe for children, accurate through plush fabric, or acceptable under a parent’s privacy expectations. The better evidence is a gate map plus test results from the actual enclosure.
The Failure Modes To Test Before Shipping
A plush wake-word system should be tested as a physical toy, not only as an audio model. The minimum test sheet should name wake latency in milliseconds, false accepts per hour of background audio, false rejects across child-spoken attempts, idle current in milliamps, and the exact ring-buffer upload policy.
Start with the background audio that will actually happen around a toy: TV dialogue, music, siblings, adult conversation, the plush’s own speaker, blanket rubbing, and the child holding the toy against their chest. Then test the wake phrase from the positions children use: mouth close to fabric, toy on lap, toy on bed, toy under a blanket edge, toy at arm’s length, and toy beside a playing speaker.
| Input condition | False wake risk | Missed wake risk | Battery impact | What to inspect |
|---|---|---|---|---|
| TV speech near the toy | High if the wake phrase is short or common | Low | High when VAD keeps the main processor awake | False accepts per hour and whether weak triggers upload a buffer |
| Child whisper at bedtime | Low | High if VAD threshold or mic placement is too strict | Low unless retries keep the session open | False rejects across at least 20 child-spoken wake attempts per age band |
| Child shout across the room | Medium from clipped audio and echo | Medium when the front end saturates | Medium from retries and repeated prompts | Input clipping, wake latency, and recovery after a failed attempt |
| Plush speaker playback | High if echo control and self-listening rules are weak | Medium when playback masks the child | High if the toy loops between speaking and listening | Wake loops, echo rejection, and local “stop” recognition during playback |
| Fabric-covered microphone | Low | High because consonants and high-frequency cues are softened | Medium from repeated wake attempts | Mic port geometry, stuffing movement, washing tolerance, and blocked-port tests |
For a prototype acceptance plan, set targets before tuning begins. A practical sheet might require wake latency below a defined child-visible limit after the phrase ends, fewer than a chosen number of false accepts per hour during mixed TV and household audio, no wake loops during a full story playback, acceptable idle current for the advertised battery life, and zero upload of pre-wake audio in offline mode. The exact numbers should match the toy’s age grade and battery size; the point is that every number maps to a gate.
False rejects deserve child-specific testing. Adult testers saying the phrase 100 times into a clean microphone do not answer the real question. Use children in the intended age range with parent consent, test multiple speaking styles, and report misses separately for whisper, normal speech, and shout. A wake phrase that works for adults but fails for children is not a small bug in an AI plush companion; it breaks the whole interaction.

Here it is in action.
The terminal animation fits the final test pass because the system should move through visible states: asleep, speech detected, wake accepted, local command mode, and cloud handoff only when allowed. If testing cannot show those transitions, a parent cannot know whether the toy stayed offline or merely delayed the upload.
The strongest offline plush wake word design is not the one with the loudest “on-device AI” claim. It is the one that names each gate, publishes the failure measurements, and keeps the child’s buffer local unless the parent has clearly enabled a cloud feature. For smart toys, the honest architecture is usually mixed: local wake and local safety commands first, optional cloud conversation later, and no mystery step in between.
References
- Picovoice Porcupine wake-word documentation
- Picovoice Porcupine FAQ on accuracy, memory, and sensitivity tradeoffs
- Espressif ESP-SR WakeNet wake-word documentation
- Google WebRTC VoiceActivityDetector source interface
- TensorFlow Lite Micro micro_speech README on the sub-20 kB model
- TensorFlow Lite Micro micro_speech example source with 10 KB tensor arena
- openWakeWord wake-word framework documentation
- 2022 systematic review of automatic speech recognition systems for children
- 2019 Frontiers review on masked speech recognition in school-age children
- FTC COPPA guidance on voice recordings from children
- CPSC toy safety FAQ on testing, certification, and ASTM F963-23


