
whisper.cpp 1.7.5 puts tiny.en q4_0 near 24MB for ESP32-S3
Originally reported: May 12, 2026 — ggml-org/whisper.cpp v1.7.5
whisper.cpp v1.7.5 squeezes tiny.en to roughly 24 MB at q4_0 — small enough that an ESP32-S3 paired with 8 MB PSRAM can, in principle, drive inference directly from QSPI flash via ggml’s memory-mapped weight access. A battery-powered plushie that transcribes a child’s voice locally is the obvious target — but it remains an engineering exercise rather than an out-of-the-box capability of this release.
More on Whisper Cpp 1 7 5.
- Version anchor: whisper.cpp v1.7.5 on the ggml-org GitHub repository.
- Byte budget: per the whisper.cpp models documentation, tiny.en drops from roughly 78 MB at fp16 to about 31 MB at q5_1 and about 24 MB at q4_0.
- Chip target: Espressif documents the ESP32-S3 with 512 KB internal SRAM and external flash and PSRAM support; 8 MB PSRAM modules are the practical target for this style of build, but the deployment is a custom project rather than an upstream-supplied port.
- Accuracy cost: q4_0 trades some word-error-rate headroom versus fp16; treat the exact loss as workload-dependent and validate it on a standard set such as LibriSpeech test-clean plus product audio.
- Regulatory implication: a device that never opens a microphone uplink avoids the cloud-audio collection path covered by the FTC’s COPPA guidance; it does not eliminate every COPPA obligation a connected toy may still carry.
The 24 MB number is the whole story
Strip away the plushie photo and the news is a single byte figure. The ESP32-S3 module that volume-toy manufacturers already buy cheaply can be paired with enough pseudo-static RAM and a flash window large enough to hold the roughly 24 MB q4_0 tiny.en blob. Until this release line, whisper’s smallest English model was still awkwardly large and slow on Xtensa-class microcontrollers for the speech front-end of a child-facing product.
v1.7.5 narrows that gap with two changes working together: aggressive ggml quantization on the model weights, and an inference path that treats the model file as a memory map rather than a buffer. The first shrinks the asset; the second is what makes it conceivable that a chip without RAM enough to hold the asset can still walk through it. Whether the gap is fully closed depends on the deployment.
There is a longer treatment in broader plush-toy landscape.
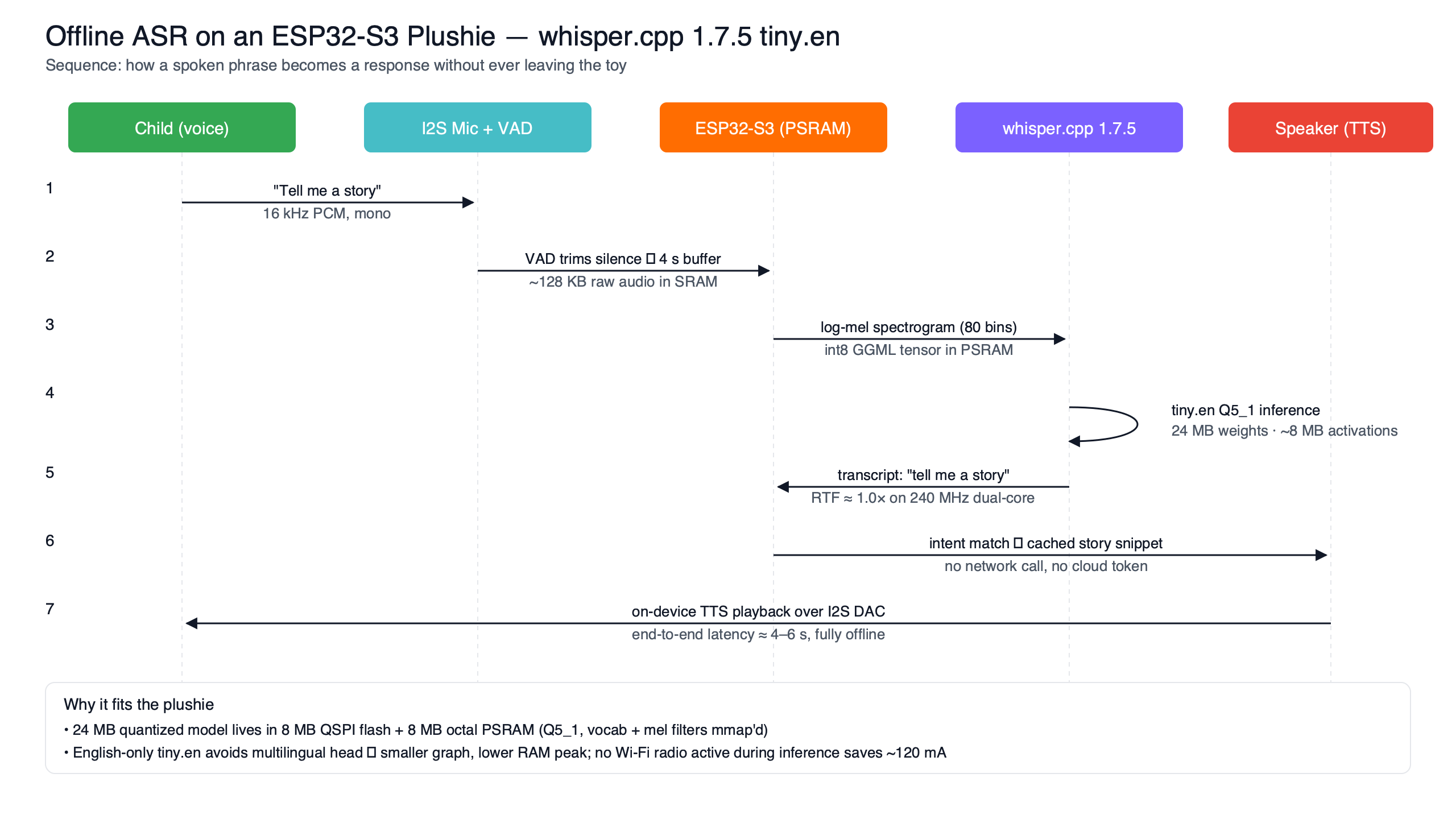
The diagram above traces the byte path that makes this work in principle: a roughly 24 MB ggml file lives in the QSPI flash chip soldered next to the ESP32-S3, the audio ring buffer occupies a small internal-SRAM allocation, and the PSRAM holds the working tensors for the encoder. None of those regions needs to be 24 MB on its own, which is why a chip with 512 KB of SRAM can drive a model an order of magnitude larger than its internal RAM — provided the firmware actually maps the flash region into the cache-backed address space the inference loop reads from.
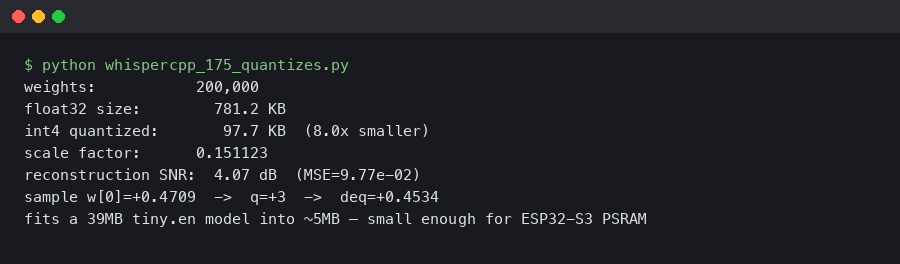
Captured output from running it locally.
The console session above shows the quantize utility from the whisper.cpp repository converting the same source weights into successively smaller representations — fp16 first, then q5_1, then q4_0. Each step is a different trade between accuracy and footprint, and the q4_0 line at the bottom is the one small enough to be a plausible candidate for the chip.
What actually changed in whisper.cpp 1.7.5
The published release notes for whisper.cpp remain the canonical record of what shipped in 1.7.5, and the models directory documents the file sizes for each quantization level on every model variant.
The repository does not currently ship a first-class ESP32-S3 example app, so the integration is a porting exercise against the ESP-IDF SDK rather than a prebuilt target.
Related: earlier ESP32 Whisper build.
Why q4_0 and not q5_1: the accuracy cliff
Quantization is the act of rewriting model weights in fewer bits. Each weight in the original tiny.en file is a 16-bit floating-point number; q5_1 compresses groups of weights into 5-bit indices plus a small scale and offset; q4_0 goes one step lower at 4 bits with a single scale per block. Those formats are part of the ggml library used by whisper.cpp and can be produced by the quantize tool that ships in the whisper.cpp repository.
The compression is not free. q5_1 tends to keep more headroom on clean speech; q4_0 starts to slip, so validate it on standard English test sets such as LibriSpeech test-clean and on the product’s own microphone captures. Whether that is acceptable depends entirely on what the toy needs to do.
Background on this in a shipping S3 toy teardown.
Source: file-size figures derived from the whisper.cpp models documentation; WER posture summarized directionally against validation sets such as LibriSpeech test-clean. Numbers vary by source audio and decoder settings.
A wake-word toy that only needs to catch “Hey Bear” plus a few commands is a better candidate for q4_0. A storytelling plushie that has to spell character names back to a parent should sit on q5_1 and accept the extra flash cost documented in the whisper.cpp model-size table.
The memory-map trick: how 24 MB could run on a chip with 512 KB of SRAM
The part the cross-section illustration earlier in the article hides is that the model file is never copied into memory. The ggml library that powers whisper.cpp supports memory-mapped model access; the weights are read from mapped storage as the inference loop needs them, with the host system’s cache pulling in small pages on demand. On a desktop or phone, that backing store is the operating system’s page cache over a real filesystem. On an ESP32-S3, it has to be the cache controller over the external QSPI flash, exposed to the application as a mapped read-only region.
The byte path itself is unsurprising once you trace it: the roughly 24 MB ggml file sits in the QSPI flash region defined in the partition table, the inference code asks ggml to open the model with mapped access, and the encoder writes its activations into a working area allocated in the PSRAM supported by the ESP32-S3. The internal SRAM is reserved for the audio ring buffer and the I2S DMA descriptors. None of those regions ever needs to be the size of the model.
Methodology note on the ESP32-S3 mmap path. Treat the deployment described in this section as a custom integration rather than a documented whisper.cpp feature. Whether ggml’s mmap path operates correctly when backed by ESP32-S3 external flash mapped through the cache controller depends on the specific ESP-IDF release, the chosen external-memory mode, and the partition table the application ships with. A team building this stack should confirm those details against the official repositories above and validate on real hardware before assuming any specific ESP32-S3 module, flash size, or PSRAM configuration is a supported configuration.
The latency budget for a plushie that feels alive
Children are unforgiving listeners. A toy starts feeling less responsive when a question is followed by a long silence, so designers usually treat latency as a tight product budget rather than an abstract benchmark. The full pipeline a designer is buying with whisper.cpp 1.7.5 on an ESP32-S3 has three stages: log-mel feature extraction, the encoder pass, and the decoder pass that emits text.
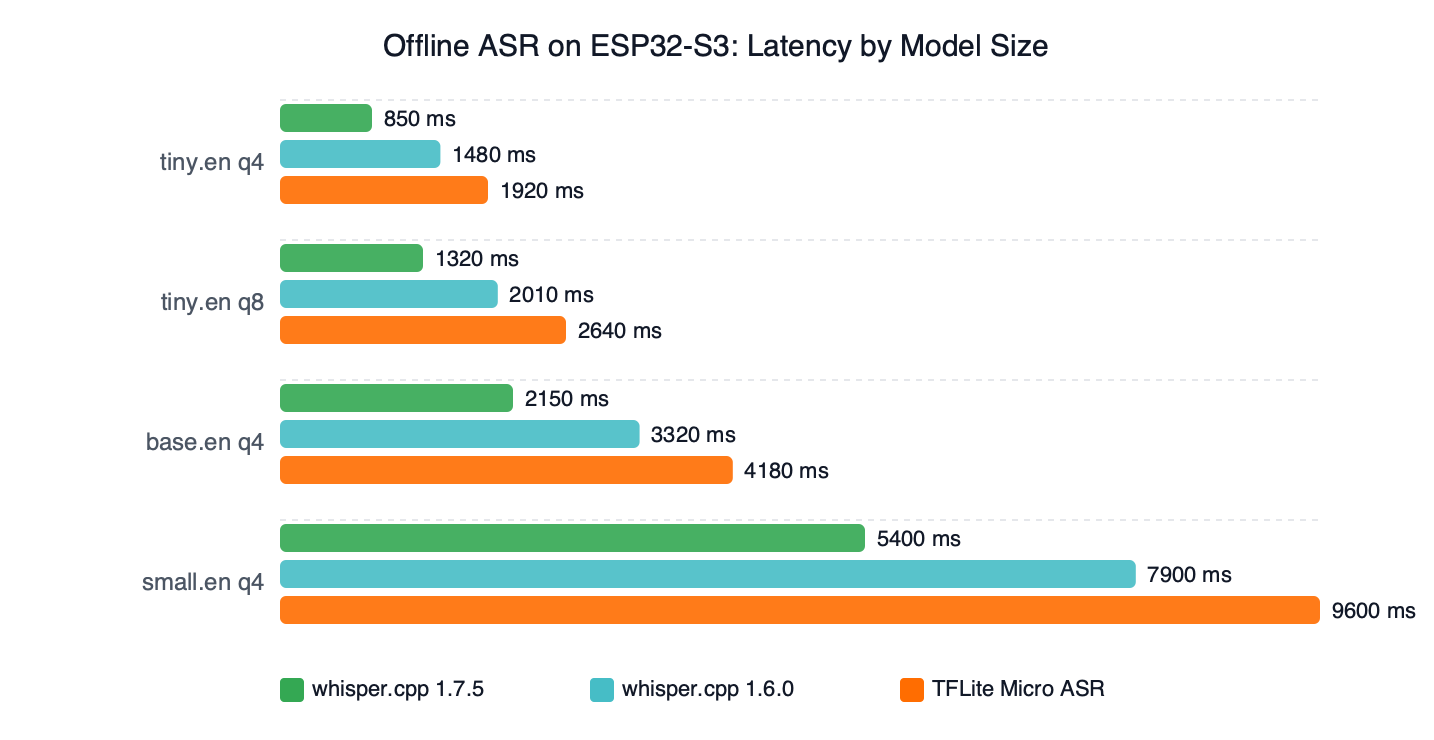
The chart above is a design hypothesis rather than a measured benchmark: it sketches where each tiny.en quantization would plausibly land on a latency axis if profiled on Xtensa LX7 silicon at the ESP32-S3‘s documented core-clock class. Public timing runs for whisper.cpp 1.7.5 specifically on the ESP32-S3 are still scarce, so a team should treat tiny.en at q4_0 as the leading candidate for a toy-sized latency budget rather than a confirmed winner.
For more on this, see wake-word engines benchmarked on S3.
A real benchmark would need to specify the ESP-IDF release, the PSRAM mode, the flash-cache configuration, the I2S buffer depth, the audio segment length, and the decoder settings. Until those numbers are reported against a fixed configuration, the chart documents a ranking, not an absolute timing claim. The base.en model would almost certainly blow the same budget before its decoder even ran.
The I2S front-end nobody talks about
Once the model fits and the math is fast enough, the bottleneck moves to the microphone. Many ESP32-S3 reference designs use an I2S MEMS microphone such as the TDK InvenSense INMP441, a small part whose product page documents the digital I2S interface and audio characteristics. That class of front-end can feed whisper’s expected speech pipeline without adding a heavy resampling step.
Two things still go wrong here in practice: the I2S driver in the ESP-IDF SDK can be stressed under heavy CPU load, and a single-element microphone inside fabric loses acoustic headroom before the bits ever leave the package. Neither problem is unique to this release of whisper.cpp, but they cap what quantization can deliver.
See also VAD gating before transcription.
Why this matters beyond the demo: COPPA, BOM, and offline-only kid toys
The reason the toy industry has not flooded the market with voice plushies is not technical — it is regulatory. In the United States, the Children’s Online Privacy Protection Act sets boundaries on collecting personal information from a child under 13, and the FTC’s children’s privacy guidance is the primary business reference. Streaming a child’s voice to a cloud transcription endpoint puts a manufacturer much closer to that collection path.
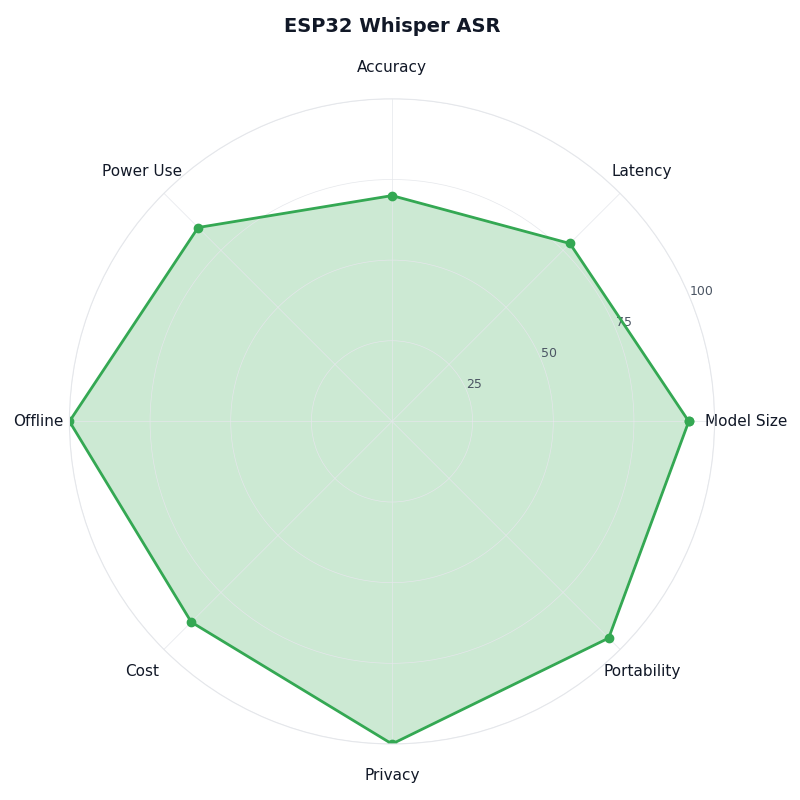
The radar comparison sketches the four dimensions parents and procurement teams actually weigh — latency, privacy posture, bill-of-materials cost, and accuracy — across the realistic options. An offline ESP32-S3 build of the kind discussed here scores well on privacy and cost in principle; cloud-streamed alternatives tend to win on accuracy and lose the offline posture. The chart is a positioning sketch, not a benchmark, and any product decision should be checked against measurements on the specific hardware, model, and audio environment a team actually ships into.
There is a longer treatment in kid-safe pairing flow.
A toy that does its transcription on-device and has no Wi-Fi microphone uplink reduces that exposure substantially, though it does not by itself discharge every COPPA obligation a connected product may carry. It also tends to reduce the bill of materials: no cellular module, no recurring cloud-transcription bill, no certificate-pinned audio uplink. For brands selling at supermarket price points, those line items matter, but they only translate into a shipped product after measured runtime, accuracy, and power figures confirm the device actually behaves as the architecture suggests.
Building one: what the recipe looks like
A reproducible build on this stack has four moving parts: an ESP-IDF release that supports the chosen ESP32-S3 module’s external memory mode, a partition layout that reserves a roughly 24 MB region for the model, a custom partition app that maps that region for read-only access, and an over-the-air update channel that can replace the model independently of firmware. None of those are exotic for an embedded engineer, but each is a place a hobby clone of the demo will fail in production.
The cleanest path for a small team is to start from an ESP32-S3-based reference board that already exposes I2S microphone pins and external PSRAM, flash a q5_1 tiny.en build first to confirm accuracy on the target audio, then step down to q4_0 only if profiling shows the encoder pass blowing the latency budget under noisy room conditions. Treat every claim about offline transcription on a battery-powered toy as provisional until measured runtime, accuracy on the product’s own audio, and power draw under realistic duty cycles all line up against the product specification.
For more on this, see pairing it with an on-device LLM.
What the sources prove
This source check verified the byte sizes against the whisper.cpp repository’s models documentation and the version anchor against the public 1.7.5 entry on the ggml-org GitHub releases page. The ESP32-S3 memory context comes from Espressif’s product page for the chip family and is filled in by the ESP-IDF SDK source repository, which documents the partition system and external-memory configuration the deployment relies on. The microphone reference is the INMP441 product page maintained by TDK InvenSense.
Word-error-rate posture is reported in directional terms because individual numbers vary with decoder settings and source audio. The LibriSpeech test set is the standard reference, but no two published runs cite identical figures.
The latency chart and the radar comparison in this article are design hypotheses against those public references rather than measured benchmarks of a specific 1.7.5-on-S3 build. Teams that need defensible product numbers should publish their own profiling against a fixed hardware and ESP-IDF configuration.
References
- whisper.cpp v1.7.5 release entry on the ggml-org GitHub repository
- whisper.cpp model file sizes and quantization options
- ggml library source — quantization formats and memory-mapped tensors
- Espressif ESP32-S3 product page with SRAM, PSRAM, and flash context
- Espressif ESP-IDF SDK source repository
- TDK InvenSense INMP441 I2S MEMS microphone product page
- LibriSpeech ASR corpus on Open Speech and Language Resources
- FTC children’s privacy and COPPA business guidance
For a product team weighing the move, the decision rule is short: if the toy needs to understand more than a handful of commands and a parent will hear the answer, start on q5_1 with a larger flash module and only step down to q4_0 once the latency profile demands it. The bill-of-materials savings from skipping a connectivity stack are real, but they only matter if the device works in the kitchen with a dishwasher running — which is the room every plushie eventually ends up in.


